

“Loving to read as a strategist”. Episode 21. The information that we read.
Today our exploration journey leads us to the subject of the information. This will be a challenging drill for me because I will not utilize any third-party references to support my text. The only outsourced articles that I have read, are some academic journals that helped me to draft the slide of the DIKW continuum, which are included in the slideshow. Alors, let´s begin.

Size: 7 x 5 plg. Paper Fabriano Traditional White. Painted with Sennelier, Holbein & Ecoline Liquid Aquarelles pigments. FOR SALE
Please download the slides that we have prepared for you. Remember that our slides are the base for the strategic reflections that we suggest afterward. You can print them in PDF, take notes or ask questions. The essence of my work is to perform strategic reflections from the knowledge that can anchor at the wisdom level for future decision-making if implemented. I am trying to go from knowledge to attain wisdom, and little by little, I am trying to write inferences that are more and more of my own derivation.
Information is not the same as knowledge.
Slide number 7 shows us the Data-Information-Knowledge-Wisdom (DIKW) pyramid framework which has several supporters, and quite a few enemies. Even in the scientific elite of researchers, we have found that some do agree with it, and have used it to build a continuum over the Ackoff pyramid; meanwhile, others attack it with passionate jargon, that lacks proof and validation. Fair enough, everyone has the right to agree or to dissent. Still, the framework is very useful, because it helps to visualize the step-by-step direction in which humans may or may not organize data, make sense of their realities, and then take decisions. The DIKW model that we have explored in the slides helps us to situate the context in which we try to see our acquisition of understanding (comprehension). I have prepared these slides, only to provide a brush of them. I have also shared below (bibliography) the most relevant information from academic papers that could help your mind amplify this subject. No matter what DIKW model will concede its evolution to our days, or if the procurement of wisdom is linear, pyramidal, or in spiral learning; be aware that probably a T. Elliot poem from the 1930s was the beginning of this theoretical distinction. It was a poem that was then deconstructed and rebuilt to be proposed by an organizational theorist as Russell A. Ackoff in the 1980s.
The slides below are a guide that includes the most common frameworks of Data, Information, Knowledge, and Wisdom (DIKW).






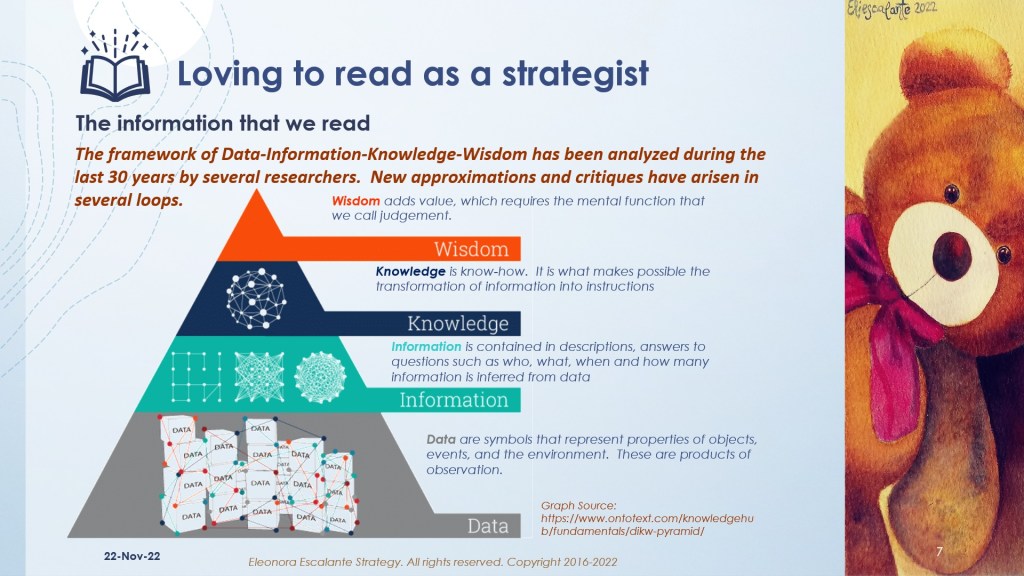

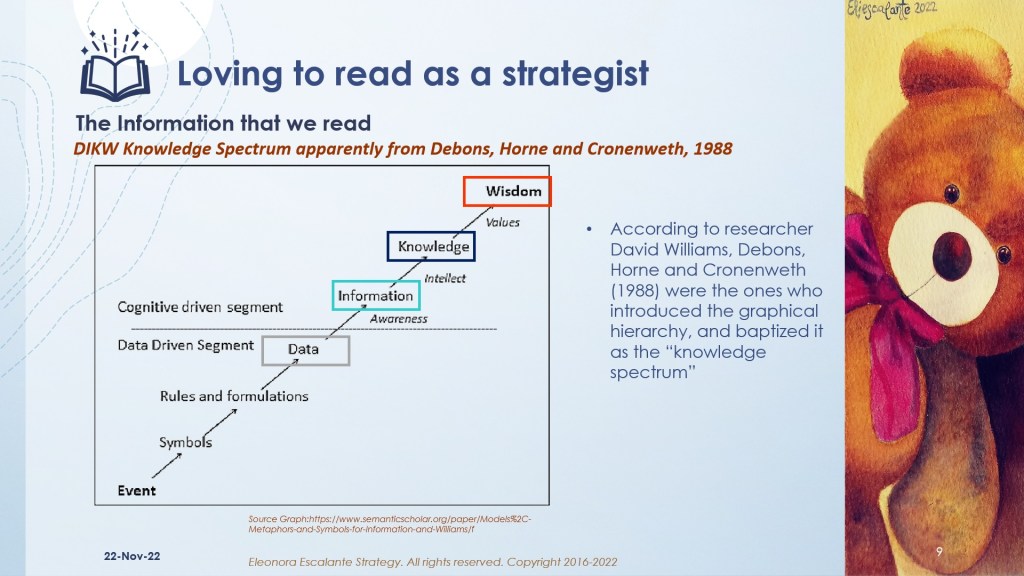
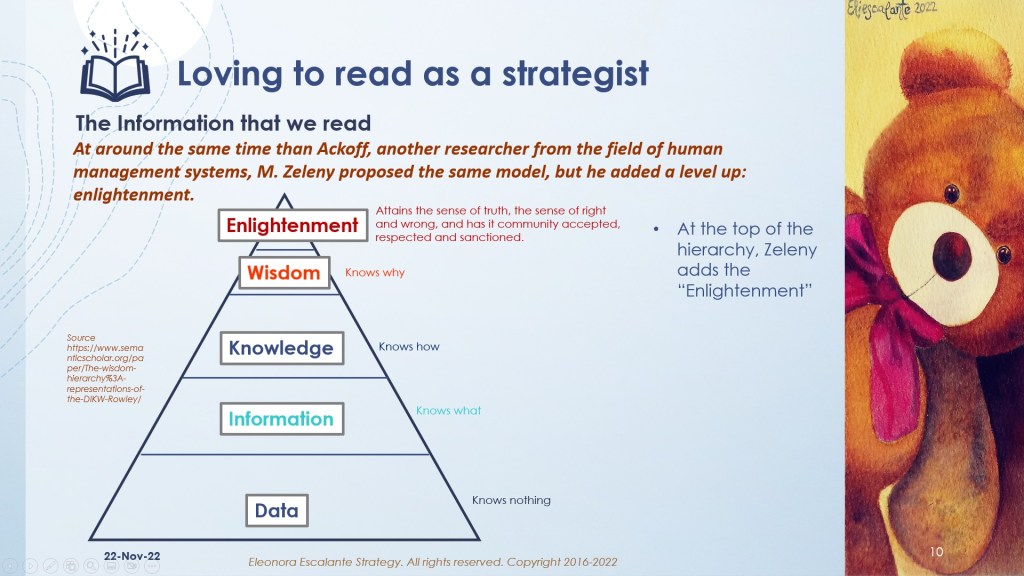
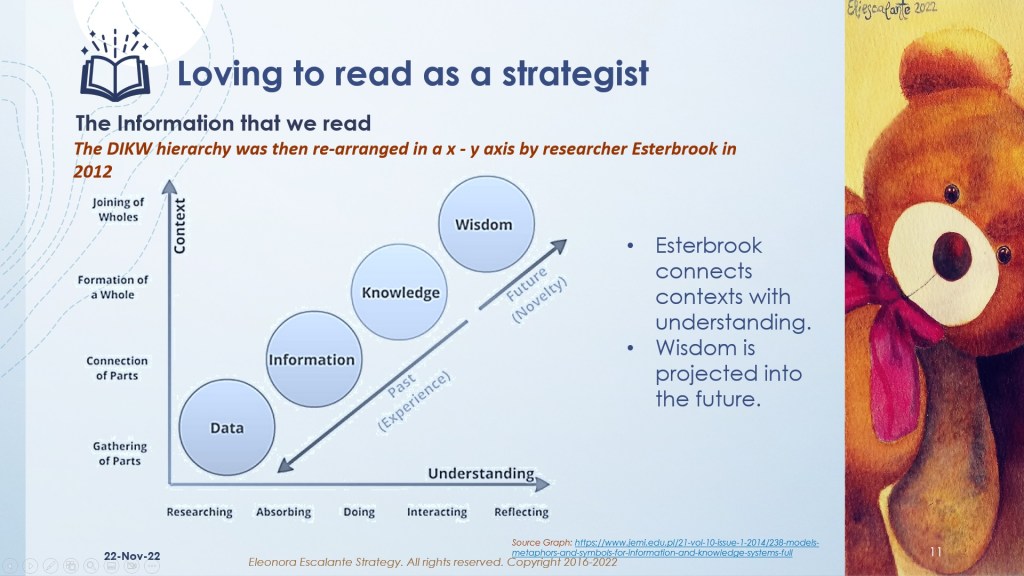




Actual attributes of the information in the digital era.
Each of the authors that have written about the DIKW model, which is cited below in the bibliography, has their own definition of information. Our aim today is not to repeat what others have written, but to show you what Eleonora Escalante Strategy has confirmed as the attributes of the information that we skim-read on the internet. Basically, more than 99% of what you find on the Internet (through browsers, applications, or social media) is merely information. In a planet where 90% of adults from developed prosperous economies don´t attain a literacy of 8th grade (Literacy 3); in a world in which 90% of adults from poorly developed countries, don’t reach a literacy of 4th grade (Literacy 2), then it is obvious that if you correlate reading with writing; I am not wrong to state that 90% of what we find on the Internet is merely information, but not knowledge. The rest of what you browse on the Internet (only 10%) is knowledge, and probably a tiny part of that 10% (maybe 1%) is related to articles that contain intelligence and wisdom. In summary: only 10% of what you find reaches the level of knowledge. These sources can be found in Google Scholar, academic web portals, journal websites, top experienced practitioners who write blogs (to be here we need at least 25 years of proven experience after university graduation), and e-libraries from prestigious universities.
We have prepared a list of attributes of the information we find on the Internet. Here we go:
- The information is abundant and immediate. any browser shows thousands of weblinks about the topic of investigation.
- The information is dirty, fuzzy, blurry, fake, and subjective. It represents the opinions of authors who many times don´t hold the minimum credentials to upload it. Or who are not well-qualified to publish or make public videos.
- The information is global. Unless the country’s Internet provider or websites blocks your entrance, anyone from anywhere can access any platform.
- The information is viral. With social media instant messaging platforms, the information that goes out from
one Smartphone can pollute or can ignite happiness in hours to billions of people in the whole world. - The information coming from social media, browsers, and apps is like a free newspaper in which all the account holders play the role of journalists.
- The information has no filters. It is not reviewed by any authority, and it is up to each creator to hold on to accountability and reliability. There is not one single tollgate that you can perceive as a filter procedure or a regulation information agency that can at least act as a parental mesh that can sift what can be uploaded or not.
- The information is dispersed for certain topics, meanwhile is copious or profuse for simple topics of our quotidian life such as cooking, fashion, make-up, or product reviews.
- The information is vulnerable. It can be hacked, even at the level of financial banking transactions. Without appropriate cyber security, anything we post on the internet is susceptible to damage, or jeopardy. Cybersecurity will be one of the most crucial themes for our humanity in the following years. On top of it, time, each person on this earth is at risk of losing copyrights, intellectual property, or content being stolen without the recognition of the credits.
- The information by online subscription has started to grow, but it will never be profitable as it was with the traditional model. Why? Because anyone can re-trade free the information online (the diffusion at the secondary market is free, and is available online). Most people in poor economies do not have credit cards either, and the cryptos need a lot of reviews yet. Digital currencies will require several years to be on point. For example, Peter can subscribe to Foreign Affairs magazine for 27 dollars per year. Peter can share articles from this magazine on his personal website, or on his Instagram-Facebook or Tiktok and he is dispersing the articles for free. Now expand the role of Peter in thousands of citizens for every country on earth.
- The information that we find on the internet is difficult to sort out, even at the academic level of publications. It requires a lot of hard work, and an enormous number of hours to identify the most reliable sources. For example, if I find an academic paper in a Google Chrome search, I usually double-check it with researchgate.com or academia.com. Then I go to other academic databases from my universities´ libraries (where I studied) to find out what other articles the author has written. Sometimes if I can´t find the original document, I must go back and forth browsing and checking the date on which it was received and accepted by the journal publishing entity. I also make sure that it has an ISSN or that a doi.org number has been assigned. Every now and then I verify if the author is teaching and if he or she has an outstanding university website in which he or she is a lecturer or researcher. I avoid wikis references. And just when I am convinced of the author’s reliability, the reading begins. All these activities consume a lot of time, even on several days when I have to sort out 20 to 30 documents for just one publication at eleonoraescalantestrategy.com.
- The information online is not systematically arranged for specific niches of people. It is a big container, in which the good knowledge that comes from the information, must be extracted with tweezers. The discernment to trust only comes with experience.
- Finally, the information online that we upload is so corrupt from faithful sources, that many times your own can be damaged or distorted by those who can´t understand your level of profoundness.

Uploading information without regulation.
Given the difficulties that we, as academic researchers encounter when getting online information, we wonder if it is time to begin to regulate what is uploaded online. The discernment that is required to sort-out knowledge from corrupted information can be amplified or confused with all the technologies around us. Let me explain with the example of the piano solos that I adore listening to when writing. Nowadays it is very hard to identify when we are listening to a real piano in comparison to a song created on a keyboard software computer. The more sophisticated are our technologies powered by artificial intelligence, the more difficult will be in the future to discern what to read online. How can we begin to apply healthy regulation for all the ones who are working in the knowledge economy? And how can we promote the protection of the excellent authors that need to make a living with their dedicated work, and are not getting anything in return?. How can we clean the Internet from the dirty, the fuzzy, and the blurry?
An opportunity for correction before proceeding further.
I will close this publication with the same image as my last episode “Pause. Breath. Repair your universe. Proceed”. Please, those who are involved in the digital economy, consider repairing and rectifying the mistakes of the online digital economy. It is now exterminating excellent authors, visual artists, and musicians, and it will continue with the rest who naively believe that they can make a living in the virtual world. The cannibalization of our own knowledge deprives us of getting the economic substance income that we deserve. The model of the Internet only offers amazing returns to those who own the main digital channels of the respective value chain, or the pioneers that got first. Then little by little when the rest starts to copycat your successful formula, and are replicated by the masses, the model works in self-destruction mode. Once a successful internet business model is known, competition goes up, pricing goes down, and without any regulation, without any barrier of entry, we are only perishing in the intent. The winners are always the big ones who have diversified businesses. The losers are always the small and medium companies that only have the resources for their unique entrepreneurship adventure. The digital economy doesn´t have barriers to entry at a global scale. And no one cares if the entrepreneur has been waiting to monetize for years, without receiving one single penny in return. It is always the bigger one who misappropriates the ideas of the genius innovator leaving her or him in disgrace and poverty. With all dreams broken. The digital economy procures these disasters, everywhere. At a global level.

Announcement: Our next Friday´s publication is “Reading as a need or as a want or as a tradition or as a fashion”.
Strategic Music Section.
Music Reading chill-outs
Today´s musical reading counsel starts with our strategic observations about the crucial aspect of discerning between our actions of skim-reading and depth-reading. Skim-reading is what we do when we scroll and read the news or when we perform what I have documented as “light-scanning” on the Internet. Skim-reading as a first step includes the effort of browsing. We use the search find key and we write or say what we need. We can do it in our favorite browser, usually Google Chrome search, or any other of the existing browsers such as Microsoft Edge, Mozilla Firefox, Vivaldi, Opera, Mac Apple Safari, Brave, etc. There are other browsers that are directly connected to social media, adapted particularly to the needs of using videos on your Smartphone. Our favorite social media platforms also function from your downloaded mobile applications. Once the browsing results come instantaneously, the labor of the user goes to inspect the surface, each of the URLs or web links that might be what we look for. Skim-reading then includes clicking on one or two or maybe three of these links (powered by artificial intelligence) and looking at them quickly.
Most of us, have no time to read aloud those articles, and we don´t even study them carefully or in detail. The only thing we do is look through the titles, and subtitles, and we only read the paragraph that we are looking for. None of us even read the whole article, particularly if it has more than 600 words. That is skim-reading. We will explore what is deep-reading (that includes comprehension) next week. We will finish this chill-out section by asking you: How many URLs or weblinks do you browse before deciding which article, paper, or video to choose? Have you thought for a minute that all those URLs or links are powered by the algorithms of artificial intelligence that your browser provider or social media platform or application decides? In the first phase of inspecting what to skim-read, we all simply click on any of the links that are chosen by your browser to appear on the first page. I think that only researchers dedicate time to browse around 5 to 10 pages (they at least skim-read the titles of at least 50 to 100 URLs). The rest of the mortals, only browse the first page. To be continued…
Our music for reading today is a collection of contemporary pianists from Halidon Music.
Carlo Balzaretti – New Age Piano Music: http://bit.ly/2osQbhb
Mario Mariani – The Soundtrack Variations: http://bit.ly/2yL4q6s
Alessandro Costantini – Many Lives: http://bit.ly/2gEoh1a
Daniele Leoni – Little Secrets & Dreams in the Mirror: https://apple.co/2GHaTAx
Zhen Ye– First Memory: http://bit.ly/2hNryfd CrusaderBeach – Piano Songs Vol. 1, 2 & 3: http://bit.ly/2y2V9Dp
Hyun Ik Kim – A Bright Day & Nostalgia: http://bit.ly/2zyRdeH
Maria Tymoshenko – Magic Flow: http://bit.ly/2gysfo0
See you next Friday 25th of November, with the 22nd episode of the saga “Loving to read as a strategist: “Reading as a need or as a want… as a tradition or as a fashion”.
Thank you for reading to me. Blessings.

“Loving to Read as a Strategist”. Illustrative and non-commercial image. Giphy source from Nazaret Escobedo
Sources of reference are utilized today.
I utilized all these references to understand the status of the Data-Information-Knowledge-Wisdom framework. Some elements of these authors have been included in the slides.
- https://www.researchgate.net/publication/279942958_Data_Information_Knowledge_Wisdom_DIKW_A_Semiotic_Theoretical_and_Empirical_Exploration_of_the_Hierarchy_and_its_Quality_Dimension
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6435353/
- https://hbr.org/2010/02/data-is-to-info-as-info-is-not
- https://onlinelibrary.wiley.com/doi/10.1002/asi.20508
- https://www.ontotext.com/knowledgehub/fundamentals/dikw-pyramid/
- https://www.researchgate.net/publication/347145057_Revising_the_DIKW_Pyramid_and_the_Real_Relationship_Between_Data_Information_Knowledge_and_Wisdom
- https://limbd.org/dikw-continuum-difference-between-information-and-knowledge-difference-between-knowledge-and-wisdom/
- https://www.jemi.edu.pl/21-vol-10-issue-1-2014/238-models-metaphors-and-symbols-for-information-and-knowledge-systems-full
- https://www.researchgate.net/publication/279205782_Knowledge_Wisdom_Leadership_and_Vision_A_Conceptual_Framework_for_Learning_Organizations
- https://www.certguidance.com/explaining-dikw-hierarchy/
- https://journals.sagepub.com/doi/10.1177/0165551508094050
- https://www.semanticscholar.org/paper/The-Data-Information-Knowledge-Wisdom-Hierarchy-and-Bernstein/
Disclaimer: Illustrations in Watercolor are painted by Eleonora Escalante. Other types of illustrations or videos (which are not mine) are used for educational purposes ONLY. All are used as Illustrative and non-commercial images. Utilized only informatively for the public good. Nevertheless, most of this blog’s pictures, images, or videos are not mine. I do not own any of the lovely photos or images posted unless otherwise stated.
Episode 21 total number of words
